The YFCC100m dataset
The YFCC100m dataset is a typical example of user-generated content that is made publicly available for anyone to use. It was published by Flickr in 2014 (Thomee et al. 1). The core dataset is distributed as a compressed archive that contains only the metadata for about 100 Million photos and videos from Flickr published under a Creative Commons License. About 48 Million of the photos are geotagged (Fig. 1).
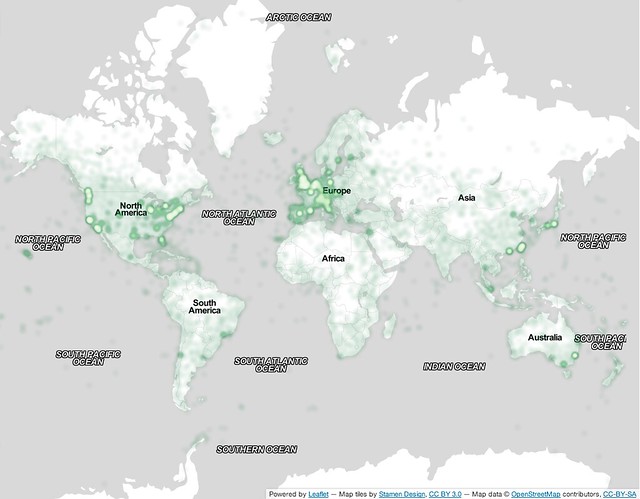
Fig. 1: „A 1 million photo sample of the 48 million geotagged photos from the dataset plotted around the globe.“ CC BY-NC 4.0 David Shamma, Flickr.
Even if user-generated data is explicitly made public, like in this case, certain risks to privacy exist. Data may be re-purposed in contexts not originally anticipated by the users publishing the data. IBM, for example, re-purposed the YFCC100m dataset to fuel a facial-recognition project, without the consent of the people in the images.
Structure
The core dataset consists of two CSV files of about 14 GB which are hosted on Amazon AWS S3 bucket. This dataset contains a list of photos and videos and related meta data (titles, tags, timestamps etc.).
An overview of available columns in this dataset is provided by Deng et al. 2. The table below contain a summary of the CSV columns.
| Column | Metadata Description | Example |
|---|---|---|
| 0 | row id | 0 |
| 1 | Photo/video identifier | 6185218911 |
| 2 | User NSID | 4e2f7a26a1dfbf165a7e30bdabf7e72a |
| 3 | User ID | 39019111@N00 |
| 4 | User nickname | guckxzs |
| 5 | Date taken | 2012-02-16 09:56:37.0 |
| 6 | Date uploaded | 1331840483 |
| 7 | Capture device | Canon+PowerShot+ELPH+310+HS |
| 8 | Title | IMG_0520 |
| 9 | Description ? | My vacation |
| 10 | User tags (comma-separated) | canon,canon+powershot+hs+310 |
| 11 | Machine tags (comma-separated) | landscape, hills, water |
| 12 | Longitude | -81.804885 |
| 13 | Latitude | 24.550558 |
| 14 | Accuracy Level (see Flickr API) | 12 |
| 15 | Photo/video page URL | https://www.flickr.com/photos/39089491@N00/6985418911/ |
| 16 | Photo/video download URL | https://farm8.staticflickr.com/7205/6985418911_df7747990d.jpg |
| 17 | License name | Attribution-NonCommercial-NoDerivs License |
| 18 | License URL | https://creativecommons.org/licenses/by-nc-nd/2.0/ |
| 19 | Photo/video server identifier | 7205 |
| 20 | Photo/video farm identifier | 8 |
| 21 | Photo/video secret | df7747990d |
| 22 | Photo/video secret original | 692d7e0a7f |
| 23 | Extension of the original photo | jpg |
| 24 | Marker (0 ¼ photo, 1 ¼ video) | 0 |
Table 1: Summary of Metadata for each CSV column available in the core dataset (yfcc100m_dataset.csv). Examples are randomly generated.
Next to this core dataset, several expansion packs have been released that provide additional data:
- Autotags: Auto tags added by deep learning (e.g. people, animals, objects, food, events, architecture, and scenery)
- Places: User provided geotags and automatically associated places.
- Exif: Additional Exif data for each photo
To follow the guides herein, only the places expansion set is is currently required.
| Column | Metadata Description | Example |
|---|---|---|
| 0 | Photo/video identifier | 6985418911 |
| 1 | Place reference (null to multiple) | 24703176:Admiralty:Suburb,24703128:Central+and+Western:Territory |
Table 2: Summary of Metadata for each CSV column available in the places expansion dataset (yfcc100m_places.csv).
References
-
Thomee, B., Shamma, D. A., Friedland, G., Elizalde, B., Ni, K., Poland, D., Borth, D., & Li, L.-J. (2016). YFCC100M: The new data in multimedia research. Commun. ACM, 59(2), 64--73. https://doi.org/10.1145/2812802 ::: ↩
-
Deng, N., & Li, X. R. (2018). Feeling a destination through the "right" photos: A machine learning model for DMOs' photo selection. Tourism Management, 65, 267--278. ::: ↩