tl;dr This guide presents an approach to privacy-aware data processing, based on geotagged photos of the YFCC100M dataset and by using SQL commands on two PostgreSQL databases through pgAdmin, visualized with Python in a Jupyter Notebook.
Abstract
Imagine someone attempting to analyze geotagged photos from Social Media, such as those found in the YFCC100M dataset, to monitor user frequentation.
This is a typical visual analytics task and it is done in many different application areas. Just one of many examples is the InVEST Project, where Flickr images are used to quantify aesthetic values and nature based tourism.
What are the ethical implications of using this data?
More specifically, the question could also be formulated: Is it ethically correct to use this data, at all?
There is an ongoing and active debate around using User Generated Content (UGC) for applications not directly considered by the people volunteering (for a summary, see See at al. 2016). The problem centers around the very definition of volunteering itself. From a narrow view, data can only be considered "volunteered" when it is used for the specific application for which it was originally collected and contributed by the people volunteering. But most data can be analyzed and used in multiple ways. In other words, data collection and data application are often two quite different things.
Consider, for example, the people volunteering cartographic data on OpenStreetMap. This is a prominent example of Volunteered Geographic Information (VGI). However, OSM data can be used for applications beyond mere cartography. Just one example is the research from Jokar et al. (2015), who analyzed inequalities of contributions on OpenSteetMap, as a means to study social and political dimensions of OpenStreetMap. Clearly, the OSM data was not volunteered for such a specific use. Does this mean that VGI should only be used for the specific context it was volunteered?
Currently speaking, most authors argue that it is not productive to limit evaluations to the original mode of data contribution (Lane et al. 2015; Metcalf & Crawford 2016). Instead, it is suggested to take into account a wider array of measures and, specifically, turn more attention towards the actual applications of data, and whether those would be considered beneficial by the people volunteering.
In the example presented here, broadly speaking, people volunteered Flickr photographs to a general and open cause, by labeling those with a Creative Commons License. We're using this volunteered data here, in a simplified example, to quantify nature based tourism. Such an application was perhaps not anticipated by the people volunteering. However, it appears possible to say that this application is beneficial to individuals or society as a whole because results may be used to support a sustainable management of tourism and nature's resources. Such implicit uses of data appear to dominate (see Ghermandi & Sinclair 2019).
Are such implicit uses of VGI considered legitimate? Since this documentation focuses on technical aspects of data processing, it is not possible to fully portray these conceptual difficulties of using crowdsourced and volunteered data. However, making sure that no personal data is available, at any step of the process, becomes of fundamental importance. The rationale is that people's privacy can be compromised, irregardless of the mode of contribution. Therefore, the process demonstrated in this tutorial applies to both, crowdsourced and volunteered data.
publication
This tutorial closely follows what is discussed in the publication:
Dunkel, A., Löchner, M., & Burghardt, D. (2020). Privacy-aware visualization of volunteered geographic information (VGI) to analyze spatial activity: A benchmark implementation. ISPRS International Journal of Geo-Information, 9(10). DOI: 10.3390/ijgi9100607
Example processing
In this specific context of application, making sure that no personal data is available, at any step of the process, becomes of fundamental importance.
There are different techniques available. The primary key to protecting user privacy is to use as little information as is possible. Particularly, not storing original user ids and post ids may efficiently prevent several attack-vectors targeted towards those who perform the data collection.
As a key measure in this example, we make use of a data abstraction called HyperLogLog (Flajolet et al. 2007), to prevent storing original distinct and highly identifiable IDs in the first place. This abstraction results in a privacy–utility tradeoff, by reducing accuracy of the final visualization by 3-5%.
However, HyperLogLog cannot protect user-privacy per se (Desfontaines et al. 2018, Reviriego & Ting 2020). But, the algorithm can be combined with other approaches that, together, largely reduce privacy conflicts.
Note
Not all implications are discussed here. For example, in the case of data published publicly, original data is available anyway. One could argue that such a situation makes any attack vector on collected data redundant. This is not the case. Firstly, it is a responsibility of any data collection authority to take individual precautions. Secondly, data published publicly may be removed at any time, requiring others to also remove data from any collected datasets. The YFCC100M dataset demonstrates that such requirement is typically impractical once original data is published, as it still contains references to many photos that have been removed in the meantime from Flickr.
In this guide, we demonstrate how to make use of a combination of techniques, to reduce the risk of privacy attacks on intermediate data collected and the final visualization published.
Techniques used:
- Query limited data (data reduction)
- Reduce spatial granularity on initial query (data accuracy)
- Cardinality estimation, instead of counting original IDs (privacy–utility trade-off, reducing accuracy by 3-5%)
As a result, the visualization and intermediate data created in this example do not require storing any original data, while at the same time retaining the capability of being continuously updated.
Preparations
To set up your environment for this guide, follow the instructions of the first two sections:
Defining the Query
We're using a two database setup:
- rawdb stands for the original social media data that is publicly available
- hlldb stands for the privacy-aware data collection that is used in the visualization environment
To query original data from rawdb, and convert to hlldb, we're using a Materialized View.
Info
Materialized views are static subsets extracted from larger PostgreSQL tables. MViews provide a performant filter for large queries. In a real-world example, data would typically be directly streamed and filtered, without the need for a Materialized View.
Create Query Schema
Create a new schema called mviews and update Postgres search_path, to include new schema:
CREATE SCHEMA mviews;
ALTER DATABASE rawdb
SET search_path = "$user",
social,
spatial,
temporal,
topical,
interlinkage,
extensions,
mviews;
Prepare query and cryptographic hashing
HyperLogLog uses MurMurHash, which is a non-cryptographic hashing algorithm. This opens up some vulnerabilities such as described by Desfontaines et al. (2018).
As an additional measurement to prevent re-identification of users in the final dataset, we are are using Postgres pgcrypto extension to hash any IDs with a secure, unique key.
Create the pgcrypto extension:
CREATE EXTENSION IF NOT EXISTS pgcrypto SCHEMA extensions;
Prepare cryptographic hash function. The following function will take an id and a key (the seed value) to produce a new, unique hash that is returned in base64 encoding.
/* Produce pseudonymized hash of input id with skey
* - using skey as seed value
* - sha256 cryptographic hash function
* - encode in base64 to reduce length of hash
* - remove trailing '=' from base64 string
* - return as text
*/
CREATE OR REPLACE FUNCTION
extensions.crypt_hash (id text, skey text)
RETURNS text
AS $$
SELECT
RTRIM(
ENCODE(
HMAC(
id::bytea,
skey::bytea,
'sha256'),
'base64'),
'=')
$$
LANGUAGE SQL
STRICT;
Tip
Cryptographic hashing alone will only produce pseudonymized data, since any id still relates to a single user (or post, etc.). Therefore, pseudonymization is considered a weak measure, which can be easily reversed, e.g. through rainbow tables or context lookup.
It is used here as an additional means to protect HLL sets from intersection attacks, as illustrated by Desfontaines et al. (2018).
What is a seed value?
The seed value (skey) is a secret that is used, together with the encryption function (e.g. sha256) to produce a unique, collision-free output value (the hashed id). The same ID will be converted to a different hash if the seed value is changed. Therefore, in our case, the seed value must remain the same during the entire processing of data. In this case, the seed is called a key. This key can be destroyed afterwards, if no subsequent updates are necessary.
Also, create the citex extension, which will be used later to apply a thematic filter to the query.
CREATE EXTENSION IF NOT EXISTS citext schema extensions;
Create GeoHash Function
In order to reduce spatial granularity to about 5km accuracy, we use a PostGis GeoHash function: ST_GeoHash
Geohash
A GeoHash of 5 means, coordinates are reduced to 5 decimal digits maximum length of lat/lng. Compare the following table:
| Precision (number of digits) | Distance of Adjacent Cell in Meters |
|---|---|
| 1 | 5003530 |
| 2 | 625441 |
| 3 | 123264 |
| 4 | 19545 |
| 5 | 3803 |
| 6 | 610 |
| 7 | 118 |
| 8 | 19 |
| 9 | 3.71 |
| 10 | 0.6 |
Table: GeoHash length and corresponding geoaccuracy in meters (Source: Wikipedia).
Create a function that takes an integer as input (the geohash accuracy).
/* Reduce spatial granularity of coordinates by GeoHash
- will keep Null Island unmodified
*/
CREATE OR REPLACE FUNCTION
extensions.geohash_reduce (IN coord geometry, geohash integer DEFAULT 5)
RETURNS geometry
AS $$
SELECT
CASE WHEN ST_Y(coord) = 0 AND ST_X(coord) = 0
THEN
coord
ELSE
ST_PointFromGeoHash(ST_GeoHash(coord, geohash), geohash)
END as "coord"
$$
LANGUAGE SQL
STRICT;
Apply topic query
In this step, several filters are applied to significantly reduce data, as a provisional measure to reduce privacy risks.
Info
For a list of all attributes available, see the LBSN Structure definition for Post.
The topic selection query below the following data reduction steps:
- filter only 'nature based reactions', based on a set of keywords
- filter only photos with geoaccuracy 'place', 'latlng' or 'city', which broadly equals Flickr geoaccuracy levels 8-16
- apply geohash to aggregate data spatially
- apply cryptographic hashing to
post_guidanduser_guid, using thecrypt_hashfunction defined earlier - reduce temporal granularity of
post_create_datetoyyyy-MM-dd
Warning
Replace samplekey with secure password.
CREATE MATERIALIZED VIEW mviews.spatiallatlng_raw_nature AS
SELECT
extensions.crypt_hash(t1.post_guid, 'samplekey') as "post_guid",
ST_Y(extensions.geohash_reduce(p1.post_latlng, 5)) As "latitude",
ST_X(extensions.geohash_reduce(p1.post_latlng, 5)) As "longitude",
extensions.crypt_hash(t1.user_guid, 'samplekey') as "user_guid",
to_char(t1.post_create_date, 'yyyy-MM-dd') as "post_create_date",
t1.post_geoaccuracy
FROM topical.post t1
WHERE
-- example for a specific query to
-- select and monitor "reactions to nature"
-- geoaccuracy minimum, equals Flickr geoaccuracy levels 8-16
t1.post_geoaccuracy IN ('place', 'latlng', 'city')
AND (
-- tags concat: check if any is contained by
-- citext format: case-insensitive text conversion
ARRAY['nature', 'natur', 'la_nature',' natuur', 'natura',
'naturo','naturae']::citext[] && t1.hashtags::citext[]
OR
-- tags separated: check if is both contained by
ARRAY['green','outside']::citext[] <@ t1.hashtags::citext[]
OR
-- words in title: check if any exists as a part of the text
-- note that underscores ( _ ) are replaced by space
-- character here
lower(t1.post_title) ilike any (
array['% nature %','% natur %','% la_nature %',
'% natuur % natura %','% naturo %','% naturae %'])
OR
-- words in post body (photo description):
-- check if any exists as a part of the text
-- note that underscores ( _ ) are replaced by space
-- character here
lower(t1.post_body) ilike any (
array['% nature %','% natur %','% la_nature %',
'% natuur % natura %','% naturo %','% naturae %'])
)
Output
SELECT 715692
Convert data from rawdb to hlldb
First, create a connection from hlldb to rawdb.
Prepare rawdb
On rawdb, create an lbsn_reader with read-only privileges for schema mviews.
Warning
Replace samplekey with secure password.
DROP USER IF EXISTS lbsn_reader;
CREATE USER lbsn_reader WITH
LOGIN
INHERIT
PASSWORD 'samplekey';
GRANT CONNECT ON DATABASE rawdb TO lbsn_reader;
GRANT USAGE ON SCHEMA mviews TO lbsn_reader;
ALTER DEFAULT PRIVILEGES IN SCHEMA mviews GRANT SELECT ON TABLES TO lbsn_reader;
Connect hlldb to rawdb
by using Foreign Table, this step will establish the connection between hlldb to rawdb.
On hlldb, install postgres_fdw extension:
CREATE EXTENSION IF NOT EXISTS postgres_fdw SCHEMA extensions;
Create Foreign Server on hlldb:
-- DROP SERVER lbsnraw CASCADE;
CREATE SERVER lbsnraw
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (
host 'rawdb',
dbname 'rawdb',
port '5432',
keepalives '1',
keepalives_idle '30',
keepalives_interval '10',
keepalives_count '5',
fetch_size '500000');
CREATE USER MAPPING for postgres
SERVER lbsnraw
OPTIONS (user 'lbsn_reader', password 'samplekey');
Import foreign table definition on the hlldb.
IMPORT FOREIGN SCHEMA mviews
LIMIT TO (spatiallatlng_raw_nature)
FROM SERVER lbsnraw
INTO extensions;
Test connection
To test the connection, get a sample result.
SELECT *
FROM extensions.spatiallatlng_raw_nature
LIMIT 1;
| column | sample |
|---|---|
| post_guid | saO.iJRzce6sM |
| latitude | 13.749921 |
| longitude | 100.491256 |
| user_guid | saLnCnBaC31Yw |
| post_create_date | 2011-03-19 |
| post_geoaccuracy | latlng |
Table 2: Sample output from extensions.spatiallatlng_raw_nature.
permission denied
In case of a "permission denied" error, execute again on raw:
GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA mviews TO lbsn_reader;
Prepare conversion of raw data to hll
We're going to use spatial.latlng from the HLL Structure definition. The structure for this table is already available, by default, in hlldb.
Create named references
To create a named table, specifically referencing thematic query context, replace spatial.latlng with any name (e.g. latlng_nature), in the query below:
CREATE TABLE spatial.latlng_nature (
latitude float,
longitude float,
PRIMARY KEY (latitude, longitude),
latlng_geom geometry(Point, 4326) NOT NULL)
INHERITS (
social.user_hll, -- e.g. number of users/latlng (=upl)
topical.post_hll, -- e.g. number of posts/latlng
temporal.pud_hll, -- e.g. number of picture (or post) userdays/latlng
topical.utl_hll -- e.g. number of terms/latlng
);
Check for previous data
Make sure that the target table spatial.latlng is empty. The following query should return no results:
SELECT *
FROM spatial.latlng
LIMIT 1;
Remove previous data
Optionally clean up previous HLL data:
TRUNCATE TABLE spatial.latlng_nature;
Optionally: optimize chunk size
Depending on your hardware, optimizing Postgres fetch_size may increase processing speed:
ALTER SERVER lbsnraw
OPTIONS (SET fetch_size '50000');
The HyperLogLog extension for Postgres from Citus that we're using here, contains several tweaks, to optimize performance, that can affect sensitivity of data.
From a privacy perspective, for example, it is recommended to disable explicit mode.
Info
When explicit mode is active, full IDs will be stored for small sets. In our case, any coordinates frequented by few users (outliers) would store full user and post IDs.
To disable explicit mode:
SELECT hll_set_defaults(11, 5, 0, 1);
From now on, HLL sets will directly be promoted to sparse.
Warning
In Sparse Hll Mode, more data is stored than in Full Hll Mode, as a means to improve accuracy for small sets. As pointed out by Desfontaines et al. 2018, this may make re-identification easier. Optionally disable sparse mode:
SELECT hll_set_defaults(11,5, 0, 0);
Aggregation step: Convert data to Hll
This is the actual data collection and aggregation step. In the query below, different metrics are collected that are typical for LBSM visual analytics (postcount, usercount, userdays).
Tip
To test, uncomment --LIMIT 100 in the query below.
INSERT INTO spatial.latlng_nature(
latitude,
longitude,
user_hll,
post_hll,
pud_hll,
latlng_geom)
SELECT latitude,
longitude,
hll_add_agg(hll_hash_text(user_guid)) as user_hll,
hll_add_agg(hll_hash_text(post_guid)) as post_hll,
hll_add_agg(
hll_hash_text(user_guid || post_create_date)
) as pud_hll,
ST_SetSRID(
ST_MakePoint(longitude, latitude), 4326) as latlng_geom
FROM extensions.spatiallatlng_raw_nature
--LIMIT 100
GROUP BY latitude, longitude;
Output
INSERT 0 62879
Immediately, it is possible to quantify spatial data reduction. The originally 715,692 coordinates (raw), were reduced to 62,879 coordinates (about 9% of original data), by using a GeoHash accuracy of 5 km. Smaller GeoHashes will further improve spatial privacy.
Visualize data
Per coordinate, the following metrics can be estimated with a 3 to 5% accuracy using the hll data:
- postcount
- usercount
- userdays
For example, to select the 100 most frequented locations for the topic "nature" and the YFCC100M dataset:
SELECT latitude,
longitude,
hll_cardinality(post_hll)::int as postcount,
hll_cardinality(pud_hll)::int as userdays,
hll_cardinality(user_hll)::int as usercount
FROM spatial.latlng_nature
ORDER BY usercount DESC
LIMIT 10;
Output
| latitude | longitude | postcount | userdays | usercount |
|---|---|---|---|---|
| 40.75927734375 | -73.98193359375 | 988 | 323 | 180 |
| 51.52587890625 | -0.10986328125 | 538 | 197 | 139 |
| 51.52587890625 | -0.15380859375 | 544 | 168 | 126 |
| 48.84521484375 | 2.35107421875 | 396 | 155 | 124 |
| 37.77099609375 | -122.45361328125 | 1169 | 160 | 103 |
| 41.37451171875 | 2.17529296875 | 319 | 123 | 94 |
| 38.86962890625 | -77.01416015625 | 803 | 203 | 90 |
| 37.77099609375 | -122.40966796875 | 1122 | 193 | 88 |
| 51.48193359375 | -0.15380859375 | 539 | 97 | 81 |
| 48.84521484375 | 2.30712890625 | 457 | 208 | 74 |
Interactive visualization in Python
Using the JupyterLab service, we can visualize this data interactively in Python.
Once jupyter lab is running, connect to http://localhost:8888/ and create a new notebook.
In the first cell, load the following visualization dependencies.
import psycopg2 # Postgres API
import geoviews as gv
import holoviews as hv
import pandas as pd
from pyproj import Transformer
from geoviews import opts
from holoviews import dim
from cartopy import crs as ccrs
from IPython.display import display
hv.notebook_extension('bokeh')
Tip
If you're using the JupyterLab service, all of these dependencies are pre-installed.
In the following Jupyter cell, enter the same SQL query, just without limiting results, to retrieve estimated data from hll db in Python.
db_connection = psycopg2.connect(
host=db_host,
port=db_port,
dbname=db_name,
user=db_user,
password=db_pass
)
db_connection.set_session(readonly=True)
db_query = f"""
SELECT latitude,
longitude,
hll_cardinality(post_hll)::int as postcount,
hll_cardinality(pud_hll)::int as userdays,
hll_cardinality(user_hll)::int as usercount
FROM spatial.latlng_nature
ORDER BY usercount DESC;
"""
df = pd.read_sql_query(db_query, db_connection)
display(df.head())
Output
| latitude | longitude | postcount | userdays | usercount |
|---|---|---|---|---|
| 40.75927734375 | -73.98193359375 | 988 | 323 | 180 |
| 51.52587890625 | -0.10986328125 | 538 | 197 | 139 |
| 51.52587890625 | -0.15380859375 | 544 | 168 | 126 |
| 48.84521484375 | 2.35107421875 | 396 | 155 | 124 |
| 37.77099609375 | -122.45361328125 | 1169 | 160 | 103 |
Create a Geoviews layer:
points_lonlat = gv.Points(
df,
kdims=['longitude', 'latitude'],
vdims=['postcount', 'userdays', 'usercount'])
Define the bounding box, for the initial zoom level of the map:
LIM_LNG_MIN = 5.174561
LIM_LNG_MAX = 21.862794
LIM_LAT_MIN = 44.465151
LIM_LAT_MAX = 49.922936
Use bboxfinder.com to select bounding box coordinates
bboxfinder.com provides a nice way for finding and selecting bbox coordinates.
And output interactive map, with circle size based on the estimation of distinct userdays (e.g).
def set_active_tool(plot, element):
"""Enable wheel_zoom in bokeh plot by default"""
plot.state.toolbar.active_scroll = plot.state.tools[0]
# project bbox coordinates
proj_transformer_mercator = Transformer.from_crs(
"epsg:4326", "epsg:3857", always_xy=True)
bb_bottomleft = proj_transformer_mercator.transform(
LIM_LNG_MIN, LIM_LAT_MIN)
bb_topright = proj_transformer_mercator.transform(
LIM_LNG_MAX, LIM_LAT_MAX)
hv.Overlay(
gv.tile_sources.EsriImagery * \
points_lonlat.opts(
tools=['hover'],
size=2+dim('userdays')*0.2,
line_color='black',
line_width=0.1,
fill_alpha=0.8,
fill_color='yellow')
).opts(
width=800,
height=480,
hooks=[set_active_tool],
title='Estimate User Count for distinct yfcc coordinates',
projection=ccrs.GOOGLE_MERCATOR,
xlim=(bb_bottomleft[0], bb_topright[0]),
ylim=(bb_bottomleft[1], bb_topright[1])
)
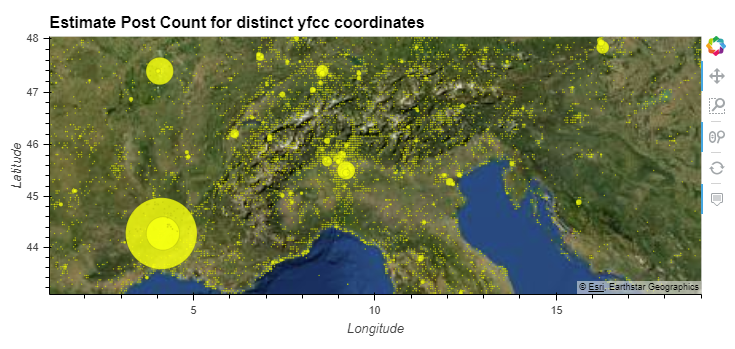 Figure 1: Userdays Map "Nature reactions" Estimated userdays per coordinate (5 km accuracy), for all YFCC100M photos that contain references to "nature".
Figure 1: Userdays Map "Nature reactions" Estimated userdays per coordinate (5 km accuracy), for all YFCC100M photos that contain references to "nature".
Have a look at the full interactive output.
Update data
Continuous Social Network data streams require frequent updates to data. Hll offers lossless union operations. These can be used to update data.
In a similar situation, an analyst may realize that some "terms" were missing in the original topic filter for raw data.
Note
Without storing raw data, it is not possible to simply re-process raw data to reflect changes to the topic filter. However, in a real-world-context, the topic filter could be adjusted from any time onwards.
Create a new topic filter for "wood", "forest" and "trees" on rawdb:
CREATE MATERIALIZED VIEW mviews.spatiallatlng_raw_wood AS
SELECT extensions.crypt_hash(t1.post_guid, 'samplekey') as "post_guid",
ST_Y(extensions.geohash_reduce(p1.post_latlng, 5)) As "latitude",
ST_X(extensions.geohash_reduce(p1.post_latlng, 5)) As "longitude",
extensions.crypt_hash(t1.user_guid, 'samplekey') as "user_guid",
to_char(
t1.post_create_date, 'yyyy-MM-dd') as "post_create_date",
t1.post_geoaccuracy
FROM topical.post t1
WHERE
t1.post_geoaccuracy IN ('place', 'latlng', 'city')
AND (
-- tags concat: check if any is contained by
-- citext format: case-insensitive text conversion
ARRAY['wood', 'forest', 'trees']::citext[]
&& t1.hashtags::citext[]
)
Output
SELECT 598,517
Import to hlldb:
IMPORT FOREIGN SCHEMA mviews
LIMIT TO (spatiallatlng_raw_wood)
FROM SERVER lbsnraw
INTO extensions;
The next step is to update spatial.latlng_nature (hll) with data from mviews.spatiallatlng_raw_wood (raw). Metrics for coordinates that already exists will be unioned (hll_union).
Tip
The specific term for ON CONFLICT ... DO UPDATE SET is UPSERT
INSERT INTO spatial.latlng_nature (
latitude,
longitude,
user_hll,
post_hll,
pud_hll,
latlng_geom)
SELECT s.latitude,
s.longitude,
hll_add_agg(
hll_hash_text(s.user_guid)) as user_hll,
hll_add_agg(
hll_hash_text(s.post_guid)) as post_hll,
hll_add_agg(
hll_hash_text(
s.user_guid || post_create_date))
as pud_hll,
ST_SetSRID(ST_MakePoint(
s.longitude, s.latitude), 4326)
as latlng_geom
FROM extensions.spatiallatlng_raw_wood s
GROUP BY s.latitude, s.longitude
ON CONFLICT (latitude, longitude)
DO UPDATE SET
-- if lat/lng already exists, union hll sets
user_hll = COALESCE(hll_union(EXCLUDED.user_hll,
spatial.latlng_nature.user_hll), hll_empty()),
post_hll = COALESCE(hll_union(EXCLUDED.post_hll,
spatial.latlng_nature.post_hll), hll_empty()),
pud_hll = COALESCE(hll_union(EXCLUDED.pud_hll,
spatial.latlng_nature.pud_hll), hll_empty());
Output
INSERT 0 59177
Note
Duplicate user IDs, post IDs or userdays will only be counted once, because this (cardinality estimation) is the fundamental function of HLL.
Retrieve updated metrics:
SELECT latitude,
longitude,
hll_cardinality(post_hll)::int as postcount,
hll_cardinality(pud_hll)::int as userdays,
hll_cardinality(user_hll)::int as usercount,
latlng_geom
FROM spatial.latlng_nature
ORDER BY usercount DESC LIMIT 10;
Output
| latitude | longitude | postcount | userdays | usercount |
|---|---|---|---|---|
| 40.75927734375 | -73.98193359375 | 2652 | 977 | 559 |
| 51.52587890625 | -0.10986328125 | 1406 | 672 | 443 |
| 51.52587890625 | -0.15380859375 | 1562 | 585 | 371 |
| 48.84521484375 | 2.35107421875 | 881 | 422 | 319 |
| 37.77099609375 | -122.40966796875 | 1688 | 550 | 267 |
| 37.77099609375 | -122.45361328125 | 1784 | 412 | 251 |
| 51.48193359375 | -0.15380859375 | 982 | 335 | 241 |
| 38.86962890625 | -77.01416015625 | 2252 | 463 | 228 |
| 41.37451171875 | 2.17529296875 | 611 | 276 | 202 |
| 37.90283203125 | -122.58544921875 | 1514 | 214 | 196 |
The order of coordinates remained roughly the same, but metrics now reflect the increased scope of the update thematic filter.
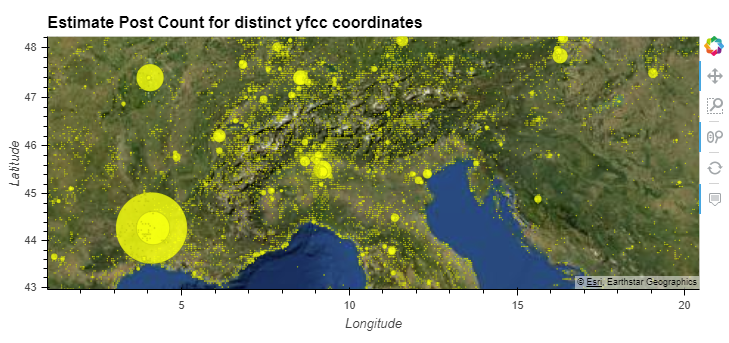 Figure 2: Updated Userdays Map "Nature reactions" Estimated userdays per coordinate (5 km accuracy), for all YFCC100M photos that contain references to "nature", including "wood".
Figure 2: Updated Userdays Map "Nature reactions" Estimated userdays per coordinate (5 km accuracy), for all YFCC100M photos that contain references to "nature", including "wood".
Have a look at the full interactive output.
Evaluation and discussion
This guide tries not to be exhaustive in what is possible, from a privacy perspective. Further, the example discussed here is very limited and highly speculative. In a real-world visual analytics workflow, a wider range of requirements would affect decisions made.
The primary motivation is to demonstrate how certain measurements can significantly reduce the risk of user re-identification in datasets collected for visual analytic. To generate the same visualization for worldwide userdays based on raw data, despite using a sparse spatial granularity, the only applicable approach would be to store each individual user ID and corresponding date.
As with all tools and approaches, there are caveats that reduce possible applications. A 3 to 5% loss of accuracy, as presented here, may be acceptable only in some contexts. Conversely, the measures taken here to protect user re-identification may be found unsuitable in other contexts. Therefore, certain risks remain.
Example
The intersection capability of Hll sets offers certain attack-vectors, which make it possible for an attacker to 'guess', with some degree of certainty, whether a user is in a set or not Flajolet et al. 2007. Particularly small sets are vulnerable to such intersection attacks. With a spatial aggregation accuracy of 5 km, there are still many small sets with only one or few users. Increasing spatial aggregation distances, or separating small Hll sets may be used to further improve privacy of users.
References
Desfontaines, D., Lochbihler, A., & Basin, D. (2018). Cardinality Estimators do not Preserve Privacy. 1–21.
Flajolet, P., Fusy, E., Gandouet, O., & Meunier, F. (2007). HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm. Conference on Analysis of Algorithms, AofA 07. Nancy, France.
Ghermandi, A., & Sinclair, M. (2019). Passive crowdsourcing of social media in environmental research: A systematic map. Global Environmental Change, 55, 36–47.
DOI
Jokar Arsanjani, J., Zipf, A., Mooney, P., & Helbich, M. (2015). OpenStreetMap in GIScience. OpenStreetMap in GIScience: Experiences, Research, Applications, 1–20. DOI
Lane, J., Stodden, V., Bender, S., & Nissenbaum, H. (2015). Privacy, Big Data, and the Public Good: Frameworks for Engagement. Cambridge: Cambridge University Press. DOI
Metcalf, J., & Crawford, K. (2016). Where are human subjects in Big Data research? The emerging ethics divide. Big Data & Society, 3(1), 205395171665021. DOI
Reviriego, P., & Ting, D. (2020). Security of HyperLogLog (HLL) Cardinality Estimation: Vulnerabilities and Protection. IEEE Communications Letters, 1–1. DOI
See, L., Mooney, P., Foody, G., Bastin, L., Comber, A., Estima, J., … Rutzinger, M. (2016). Crowdsourcing, citizen science or volunteered geographic information? The current state of crowdsourced geographic information. ISPRS International Journal of Geo-Information, 5(5). DOI