Privacy
Our conception of privacy can be summarized with the following definition.
Quote
The very act of data collection, whether it is legal or illegal, is the starting point of various information privacy concerns. We define collection, the first dimension of IUIPC [Internet users' information privacy concerns], as the degree to which a person is concerned about the amount of individual-specific data possessed by others relative to the value of benefits received. This collection factor is grounded on [Social Contract's] principle of distributive justice, which relates to "the perceived fairness of outcomes that one receives" (Culnan et al. 1). In an equitable exchange, consumers give up some information in return for something of value after evaluating the costs and benefits associated with the particular transaction. Thus, individuals will be reluctant to release their personal information if they expect negative outcomes (Cohen et al. 2, Malhotra et al. 3).
We also introduce the founding concept and ideas in a dedicated publication 4.
A basis for communication
Our rationale is that only an open discussion and a clear communication can help improving user privacy on a broad basis. While many approaches to enhancing user privacy already exist, specific methods are sometimes difficult to adapt or follow.
With the examples provided in this guide, we attempt to cover all steps of processing. This allows us to illustrate and discuss approaches to privacy-protection in-depth and in a detailed fashion, particularly beyond what is possible in peer-reviewer papers.
Limitations apply
We emphasize that the examples presented here are not universally applicable. Privacy conflicts emerge from specific contexts of application, and it is not possible to declare rules that apply to all possible contexts.
Particularly, this guide provides no legal advice whatsoever. The demonstrations provided here can provide a basis for anyone voluntarily interested in enhancing data processing workflows.
Enhancing privacy-awareness
Many approaches and methods have been published to help mitigating privacy risks and to improving data protection, for various application areas.
However, we observe that application of methods in practice lags behind theoretic advances. One of the reasons, from our perspective, is that it is often challenging to transfer and adapt theoretic approaches to concrete practical applications and the actual implementation of code.
With the LBSN Structure, we attempt to bridge this gap.
The challenge of enhancing privacy awareness in a broad range of LBSM visual analytics can be broken down in the following two key tasks:
-
LBSN RAW Structure: A systematic data format for UGC
We propose a data scheme that can be used to systematically describe and handle data from various LBSM in a common format. Our rationale is that not all LBSN data is equally relevant to user privacy, and knowing which aspects need particular attention is the first step to enhancing privacy-awareness in actual implementation contexts. Thus, the main goal of the LBSN Structure is to provide a transparent base for open communication.
We call individual pieces of the LBSN Structure Bases. -
LBSN HLL Structure: Privacy-aware visual analytics
The LBSN HLL Structure is geared towards visualization. HLL refers to HyperLogLog, an algorithm for approximate data abstraction. Not all visual analytic applications, work flows and contexts are equally relevant to privacy. Therefore, a first step is to systematically describe various metrics used in current LBSM RAW structure. Based on these metrics, we can discuss and describe best practice examples for enhancing user privacy.
Metrics can be measured and visualized for any Base. Typical metrics, currently considered in the structure, are post count, user count, or user days, see metrics.
Application contexts
The current implementation of the LBSN Structure particularly considers data shared on current Social Media that is explicitly made available to the public. While UGC can encompass a diverse range of datasets, specific challenges to user privacy protection emerge when data is publicly shared, either voluntarily or involuntarily (unknowingly). Such data potentially offers attack-vectors, e.g. to compromise privacy, at various steps of its lifetime.
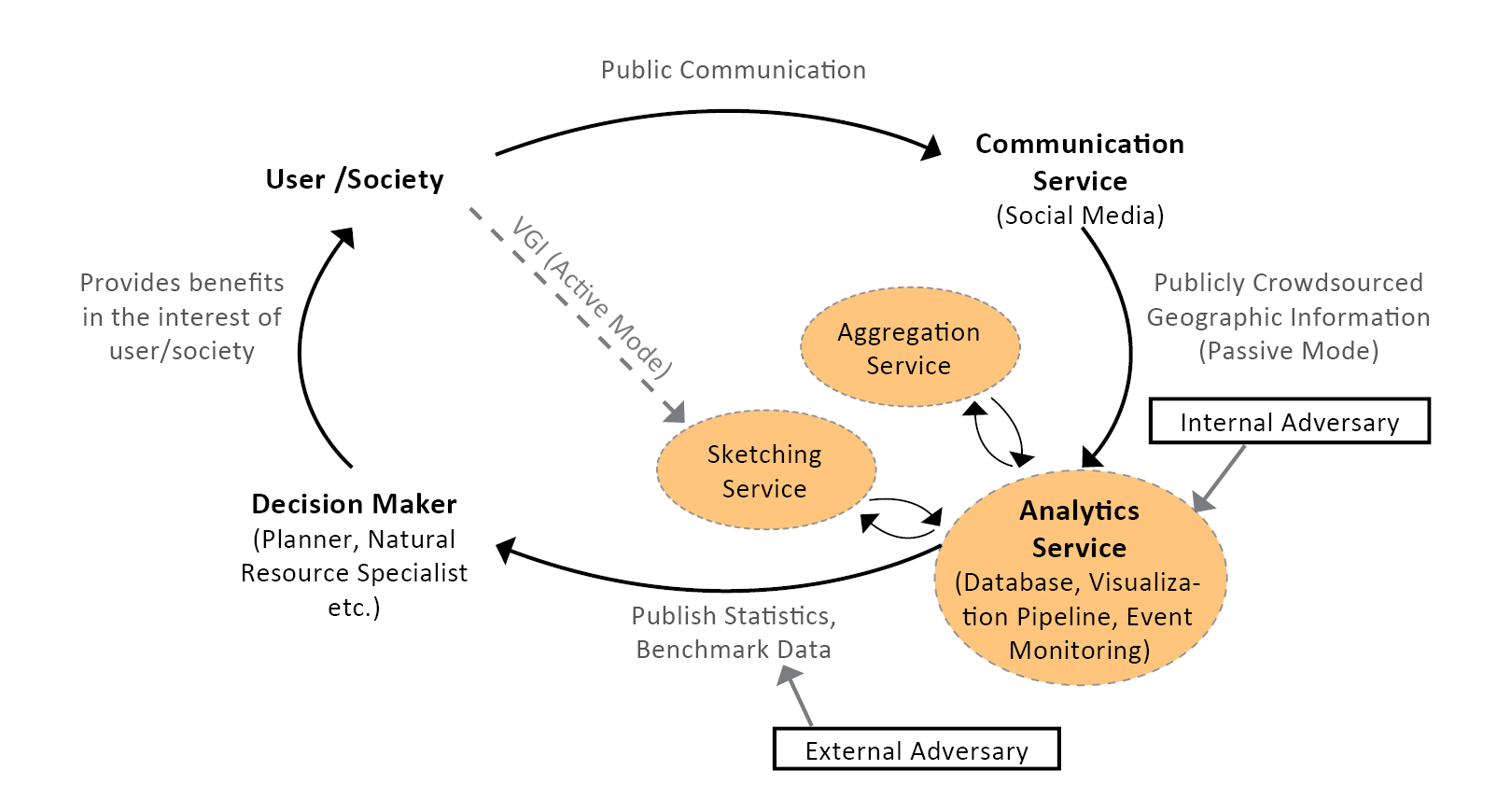
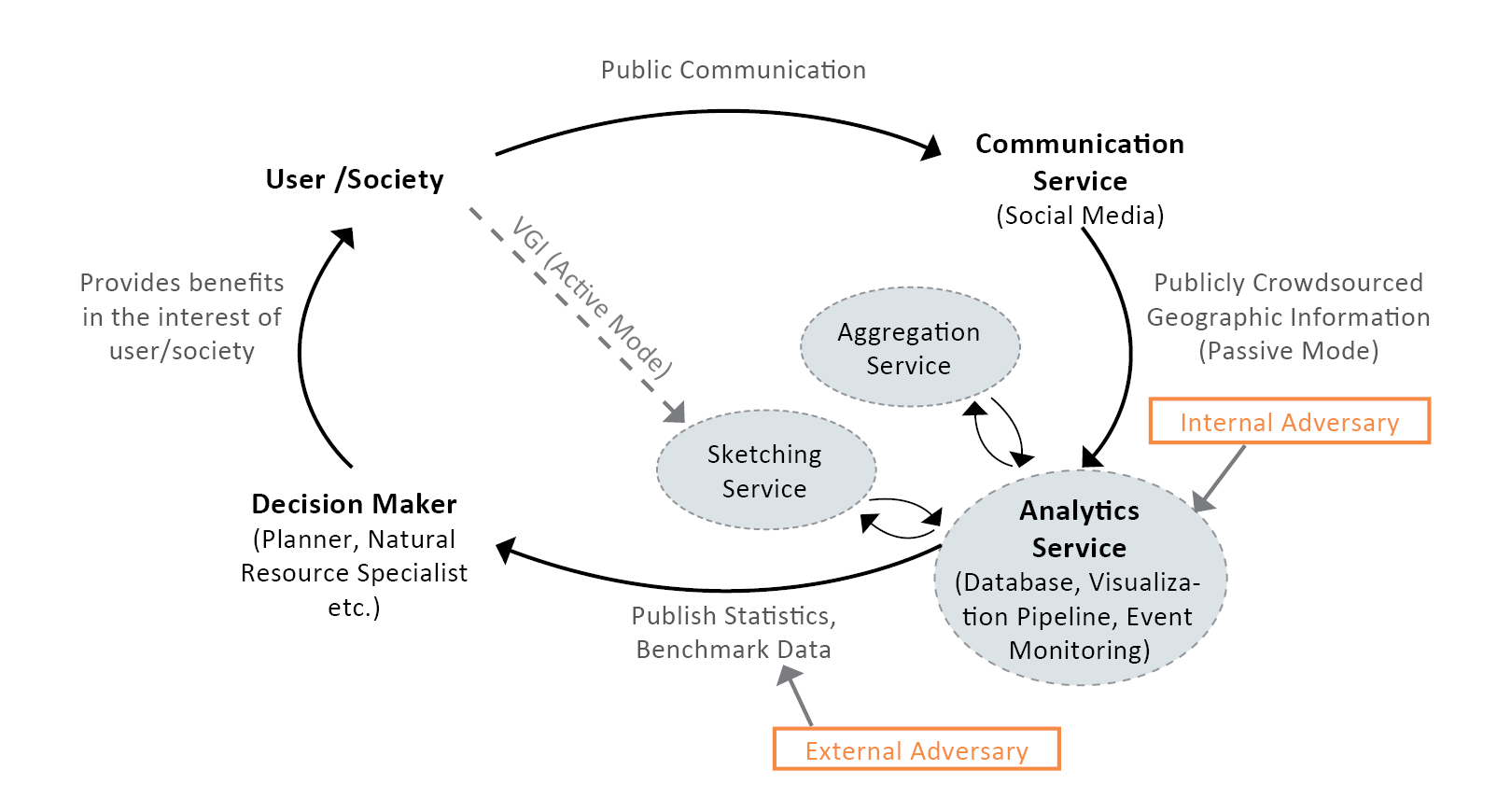
Fig. 1: General System Design, illustrating the application and privacy context. (Dunkel et al. 2020 4).
Therefore, even data used in ethically sound applications, making use of the data in the users´ personal interests, may be re-purposed, for example, to compromise user privacy. Our primary intent is to minimize risk in these specific situations, where the application of data is the shared interest of user and authority.
Since LBSN visual analytics is a broad field, neither the structure nor the discussion of application contexts presented here is exhaustive. Furthermore, the conception of privacy and accepted practices changes rather fast. We invite contributions to enhance and extend the current scope of the concept, structure and best practice examples.
HyperLogLog
In a conference paper, a general conceptual frame for systematically improving privacy-awareness in various visual analytic questions has been proposed (Löchner et al. 2019 5). In this conceptual frame, using HyperLogLog, a cardinality estimation algorithm (Flajolet et al. 2007 6), is proposed as a key to gradually mitigating privacy risks during various steps of the analytical process.
By solving the count distinct problem, HyperLogLog can be directly applied to key metrics used in LBSN visual analytics such as user count, post count, or user days. However, since HyperLogLog is not, per se, privacy preserving, it must be combined with other approaches and components (Desfontaines et al. 2018 7).
In a subsequent full paper by Dunkel et al. 2020 4, this is demonstrated in detail for one specific type of visualization: A grid based aggregation of typical metrics such as post count, user count or user days. The results can be replicated with several jupyter notebooks provided in supplementary materials.
In the Tutorial & User Guide section here, we demonstrate several additional examples how the LBSN Structure can be applied, and present and discuss several approaches to privacy-aware processing.
Note
This metric-section of the LBSN Structure is in a very early stage of development. Ideally, we hope that this section can be revised frequently to reflect a broader range of application contexts in the future.
-
Culnan, M. J., & Bies, R. J. (2003). Consumer privacy: Balancing economic and justice considerations. Journal of Social Issues, 59(2), 323--342. https://doi.org/10.1111/1540-4560.00067 ::: ↩
-
Cohen, R. L. (1987). Distributive justice: Theory and research. Social Justice Research, 1(1), 19--40. https://doi.org/10.1007/BF01049382 ::: ↩
-
Malhotra, N. K., Kim, S. S., & Agarwal, J. (2004). Internet users' information privacy concerns (IUIPC): The construct, the scale, and a causal model. Information Systems Research, 15(4), 336--355. https://doi.org/10.1287/isre.1040.0032 ::: ↩
-
Dunkel, A., Löchner, M., & Burghardt, D. (2020). Privacy-aware visualization of volunteered geographic information (VGI) to analyze spatial activity: A benchmark implementation. ISPRS International Journal of Geo-Information, 9(10). https://doi.org/10.3390/ijgi9100607 ::: ↩↩↩
-
Löchner, M., Dunkel, A., & Burghardt, D. (2019). Protecting privacy using HyperLogLog to process data from location based social networks. Proceedings of the Legal Ethical factorS crowdSourced geOgraphic iNformation, 1--7. ::: ↩
-
Flajolet, P., Fusy, É., Gandouet, O., & Meunier, F. (2007). Hyperloglog: The analysis of a near-optimal cardinality estimation algorithm. Discrete Mathematics and Theoretical Computer Science, 137--156. ::: ↩
-
Desfontaines, D., Lochbihler, A., & Basin, D. A. (2018). Cardinality estimators do not preserve privacy. CoRR, abs/1808.05879. http://arxiv.org/abs/1808.05879 ::: ↩